Building Your Own SoC#
This tutorial will walk you through the process of building an ASIC containing one PicoRV32 RISC-V CPU core and 2 kilobytes of SRAM, on an open-source 130nm Skywater process node, with SiliconCompiler’s remote workflow:
We will walk through the process of downloading the design files and writing a build script, but for your reference, you can find complete example designs which reflect the contents of this tutorial in the public SiliconCompiler repository. The first part of the tutorial will cover building the CPU core without RAM, and the second part will describe how to add an SRAM block.
See the Installation section for information on how to install SiliconCompiler, and the Remote Processing section for instructions on setting up the remote workflow.
Download PicoRV32 Verilog Code#
The heart of any digital design is its HDL code, typically written in a language such as Verilog or VHDL. High-level synthesis languages are gaining in popularity, but most of them still output their final design sources in a traditional HDL such as Verilog.
PicoRV32 is an open-source implementation of a small RISC-V CPU core, the sort you might find in a low-power microcontroller. Its source code, license, and various tooling can be found in its GitHub repository.
Build the PicoRV32 Core using SiliconCompiler#
Before we add the complexity of a RAM macro block, let’s build the core design using the open-source Skywater 130 PDK.
Copy the following build script into the same directory which you copied picorv32.v into.
A complete example build script can be found in the repository.
Note in the code snippet above that [option,remote] is set to False. If this is set to True, this means it is set up for remote processing, and if you run this example as a Python script, it should take approximately 20 minutes to run if the servers are not too busy.
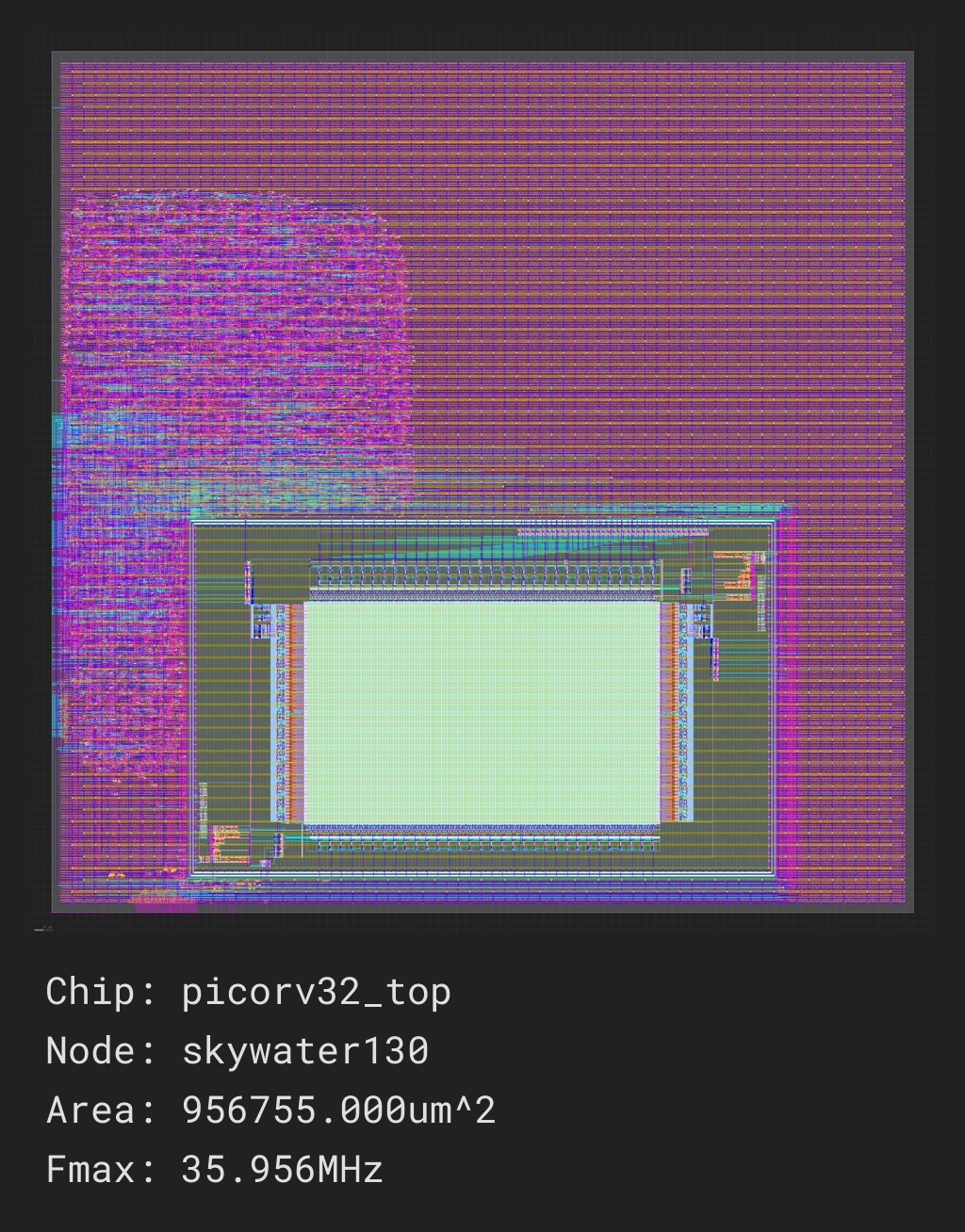
We have not added a RAM macro yet, but this script will build the CPU core with I/O signals placed pseudo-randomly around the edges of the die area.
Once the job finishes, you should receive a screenshot of your final design, and view the dashboard with sc-dashboard -cfg build/picorv32/job0/picorv32.cfg.
SiliconCompiler will try to open the file after the job completes, but it may not be able to do so if you are running in a headless environment.
For the full GDS-II results and intermediate build artifacts, you can run the build locally. See the local run section for more information.
Adding an SRAM block#
A CPU core is not very useful without any memory. Indeed, a real system-on-chip would need quite a few supporting IP blocks to be useful in the real world. At the very least, you would want a SPI interface for communicating with external non-volatile memory, a UART to get data in and out of the core, a debugging interface, and a small on-die cache.
In this tutorial, we’ll take the first step by adding a small (2 kilobyte) SRAM block and wiring it to the CPU’s memory interface. This will teach you how to import and place a hard IP block in your design.
The open-source Skywater130 PDK does not currently include foundry-published memory macros. Instead, they have a set of OpenRAM configurations which are blessed by the maintainers. You can use those configurations to generate RAM macros from scratch if you are willing to install the OpenRAM utility, or you can download pre-built files.
We will use the sky130_sram_2kbyte_1rw1r_32x512_8 block in this example.
Create a Python script called sky130_sram_2k.py to describe the RAM macro in a format which can be imported by SiliconCompiler.
Example files for the complete SoC design can be found in the repository.
With all of that done, your project directory tree should look something like this:
<rundir>
├── sky130_sram_2k.bb.v
├── sky130_sram_2k.py
├── picorv32.py
├── picorv32_ram.py
└── picorv32_top.v
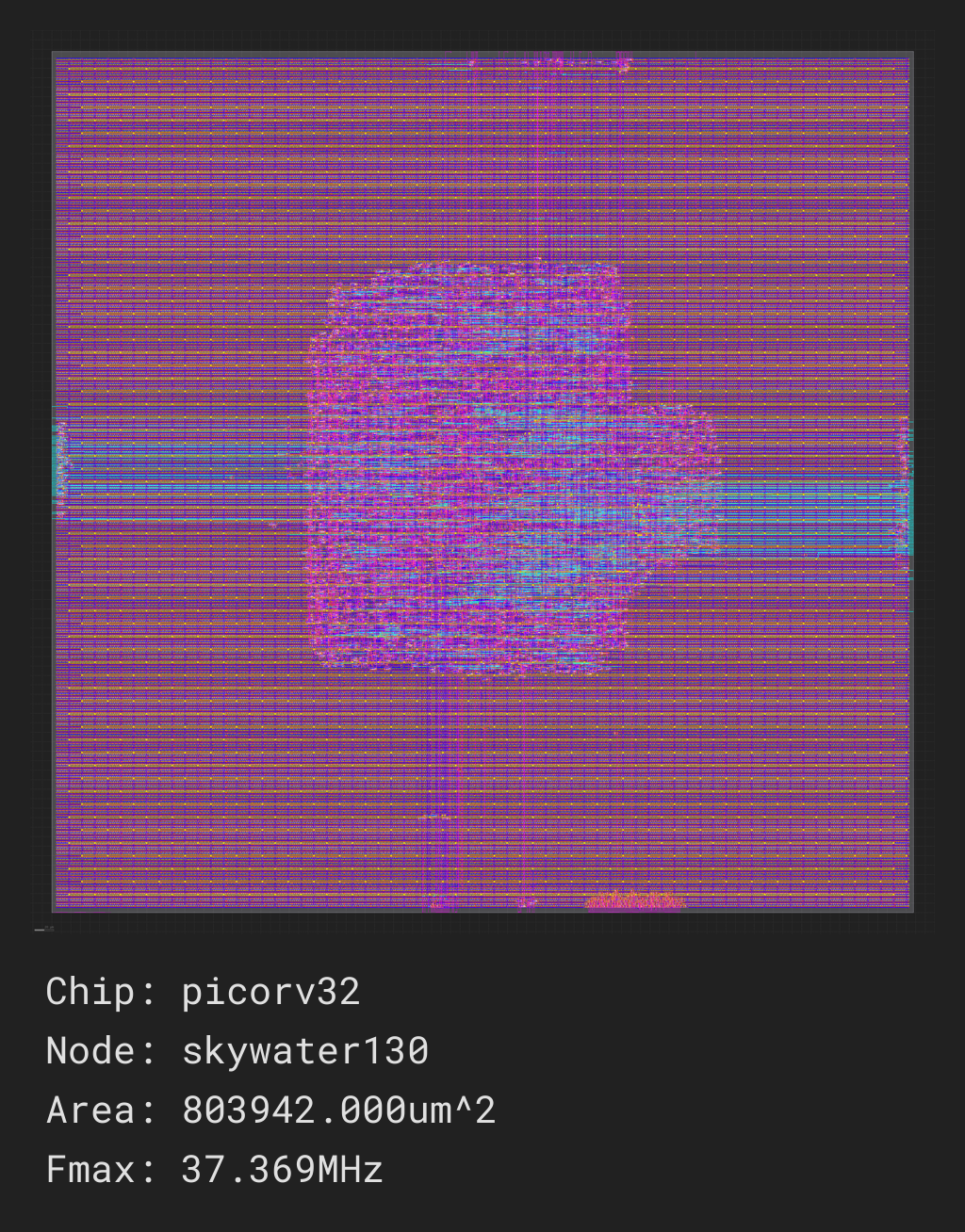
Your picorv32_ram.py build script should take about 20 minutes to run on the cloud servers if they are not too busy, with most of that time spent in the routing task.
As with the previous designs, you should see updates on its progress printed every 30 seconds, and you should receive a screenshot once the job is complete and a report in the build directory:
Extending your design#
Now that you have a basic understanding of how to assemble modular designs using SiliconCompiler, why not try building a design of your own creation, or adding a custom accelerator to your new CPU core?